1. 神经网络基础
1.1 感知机
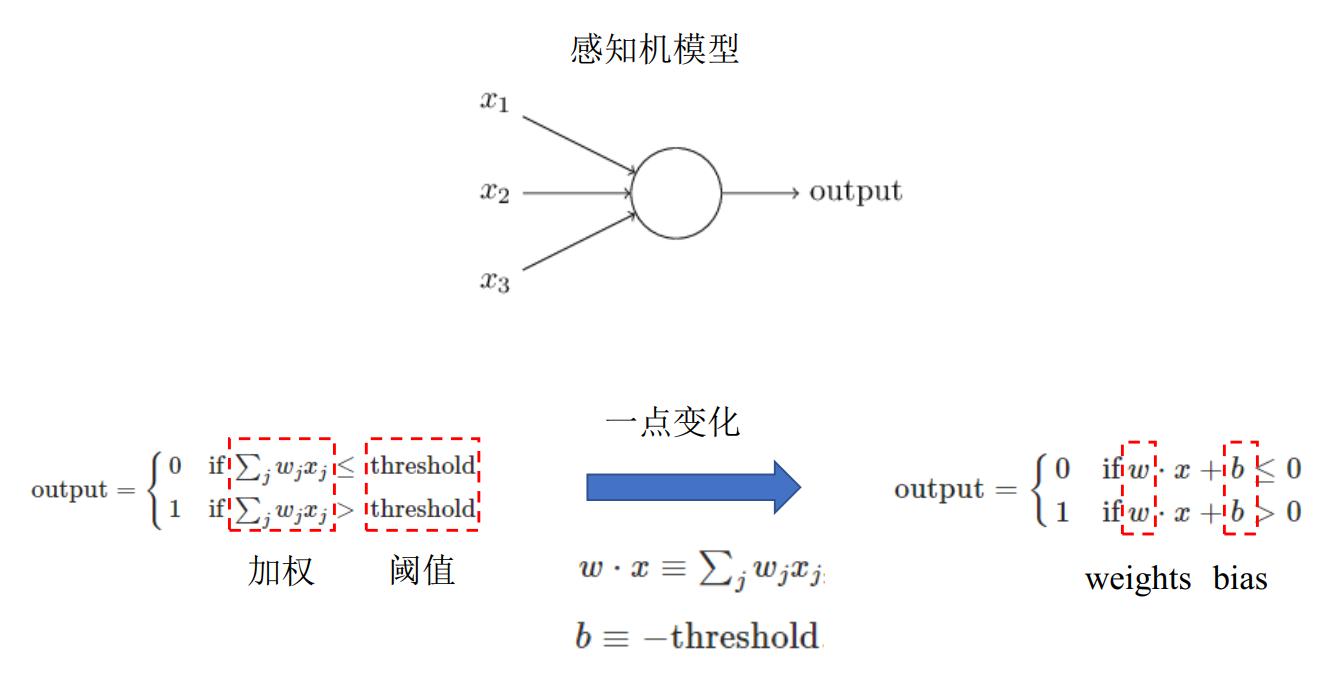
感知机堆叠可以形成一个庞大的网状结构。
=> 但是通过感知机设计一个学习方案比较困难,因为通过该模型的输出时0和1,调参看不出明显的变化,即没有很好的反馈,并不能很好的设置w、b。
1.2 神经网络的结构
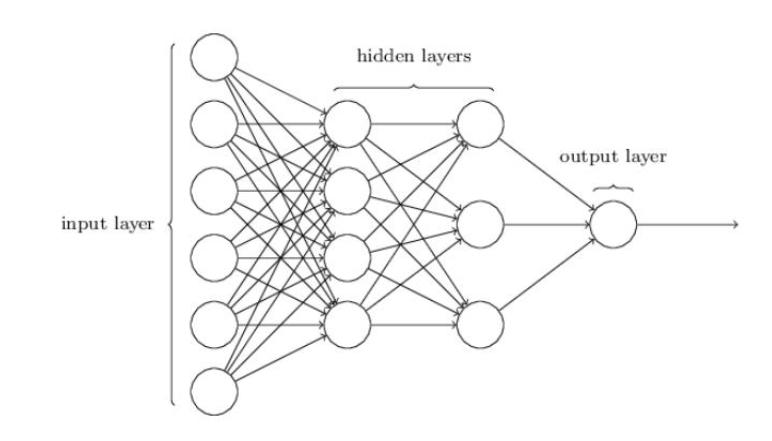
input_layer:输入层
hidden_layer:隐藏层
output_layer:输出层
1.3 优化网络参数

如何优化
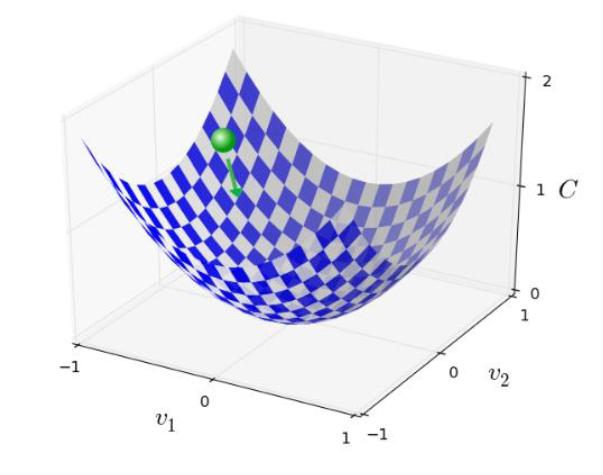
假设现在只考虑俩个变量v1和v2,不同情况下的代价函数如左图所示,我们希望优化参数使得总体损失最小。假设有一个小球放置在任意一点,那么受到重力影响,小球会滚下去,最终停在谷底。那么,小球滚下去的过程就是我们希望的优化的过程。
在小球下降的过程中,可以看作小球分别沿着v1、v2方向下降。那么,如果我们分别将小球沿v1、v2分别移动一个小量,就可以改变代价值。
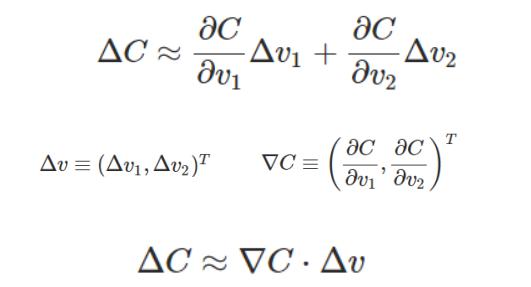
为了保证优化到最优,也就是C值最小,我们在优化过程中需要保证△C小于0,而AC取决于VC和△v的乘积,当函数形式和参数固定时,其梯度VC也固定了,但我们可以指定△v的值:
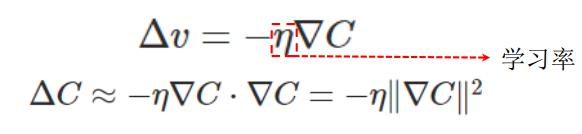
但是,不要忘记,我们真正关心的其实是参数v,因为v才是我们的优化目标:
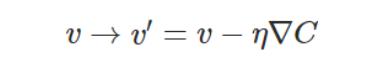
如何计算梯度
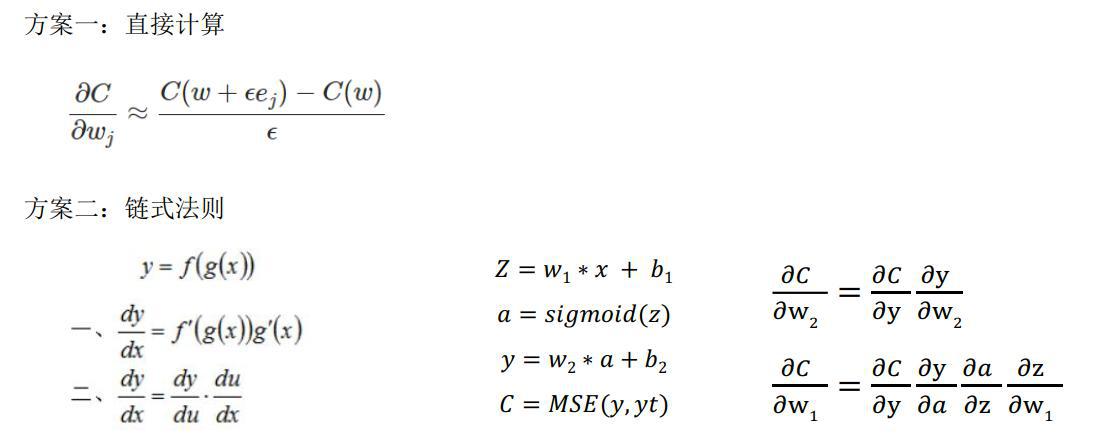
两种方案有什么优缺点:
- 二者在准确度上几乎无差异。
- 直接计算方式:公式简单,代码实现难度较大。
- 链式法则:公式较直接计算方式复杂,代码实现较易。
SGD

- SGD:只采集单个数据
- mini-batch SGD:采集小批量数据
- fullbatch Gradient Descent:采集整个数据集
2. 让网络更有效
2.1 MSE 与交叉熵
损失函数用于描述模型预测值与真实值的差距大小,一般有两种比较常见的算法——均值平方差(MSE)和交叉熵。
我们希望网络优化的力度,应该跟网络预测结果的偏差相关,即当网络预测偏
差较大时,网络优化力度大;当网络预测偏差较小时,网络优化力度较小。
1、均值平方差(MSE):指参数估计值与参数真实值之差平方的期望值。
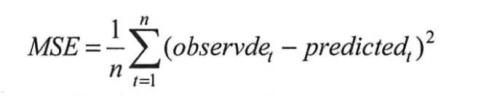
在神经网络计算时,预测值要与真实值控制在同样的数据分布内,假设将预测值经过Sigmoid激活函数得到取值范围在01之间,那么真实值也归一化到01之间。
2、交叉熵:预测输入样本属于某一类的概率。
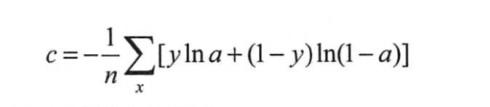
其中y代表真实值分类(0或1),a代表预测值,交叉熵值越小,预测结果越准。
3、损失函数的选取
损失函数的选取取决于输入标签数据的类型,如果输入的是实数、无界的值,损失函数使用平方差;如果输入标签是位矢量(分类标签),使用交叉熵会更合适。
2.2 正则化( regularization)
仅仅依靠交叉熵或者MSE损失对网络进行约束, 虽然能让网络不断拟合训练数据, 但是这样拟合的方式可能不是我们想要的, 比如导致过拟合。 在这种情况下, 为了让网络按照我们想要的方式学习, 我们可以引入正则化项来对网络进行进一步的约束。
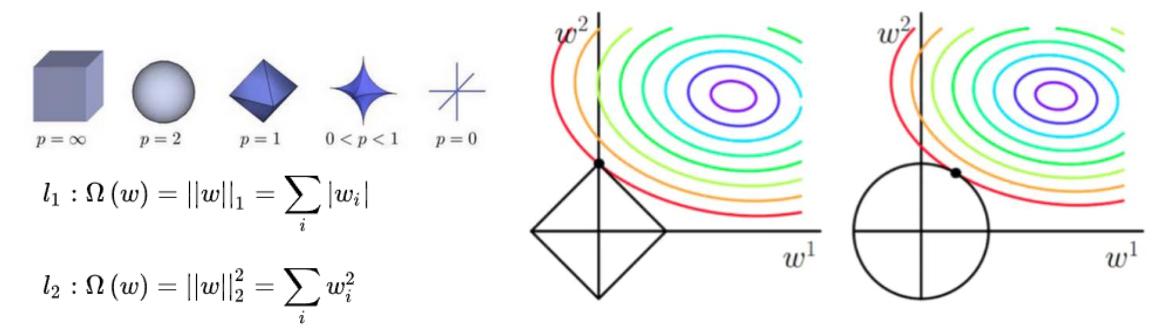
- L1范数: 为x向量各个元素绝对值之和,简化模型,使权值稀疏,防止过拟合。
- L2范数: 为x向量各个元素平方和的1/2次方,让模型平滑,也可以防止过拟合。
- Lp范数: 为x向量各个元素绝对值p次方和的1/p次方.
2.3 参数初始化
- 0初始化: https://mp.weixin.qq.com/s/OcEqqQq59adjZqBsh_7Zw
- 随机初始化:随机初始化的时候常常采用高斯或均匀分布初始化网络权重,但可能会出现梯度消失和梯度爆炸现象。
- Xavier初始化:通过保持输入和输出的方差一致(服从相同的分布)避免梯度消失和梯度爆炸问题,使得信号在神经网络中可以传递得更深,在经过多层神经元后保持在合理的范围(不至于太小或太大)
2.4 激活函数改进
激活函数定义
在神经网络中,输入经过权值加权计算并求和之后,需要经过一个函数的作用,这个函数就是激活函数(Activation Function)。
激活函数的作用
首先我们需要知道,如果在神经网络中不引入激活函数,那么在该网络中,每一层的输出都是上一层输入的线性函数,无论最终的神经网络有多少层,输出都是输入的线性组合;其一般也只能应用于线性分类问题中,例如非常典型的多层感知机。若想在非线性的问题中继续发挥神经网络的优势,则此时就需要通过添加激活函数来对每一层的输出做处理,引入非线性因素,使得神经网络可以逼近任意的非线性函数,进而使得添加了激活函数的神经网络可以在非线性领域继续发挥重要作用!
更进一步的,激活函数在神经网络中的应用,除了引入非线性表达能力,其在提高模型鲁棒性、缓解梯度消失问题、将特征输入映射到新的特征空间以及加速模型收敛等方面都有不同程度的改善作用!
Sigmoid:
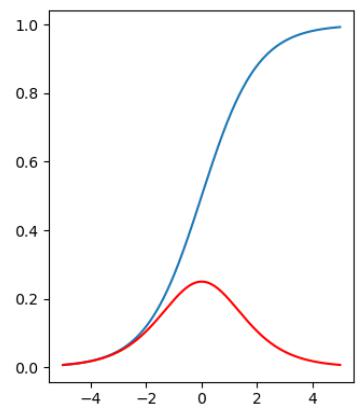
- 优点:
- Sigmoid的取值范围在(0, 1),而且是单调递增,比较容易优化
- Sigmoid求导比较容易,可以直接推导得出
- 缺点:
- sigmoid整体梯度较小, 最大只有0.25, 随着网络层数的加深梯度将逐渐减小, 造成梯度消失, 导致训练困难
- sigmoid俩端平滑, 容易饱和, 只对中间区域敏感, 不利于参数学习
- sigmoid的输出不是zero-centered , 使得前后特征分布容易发生改变
- Sigmoid函数收敛比较缓慢
Tanh
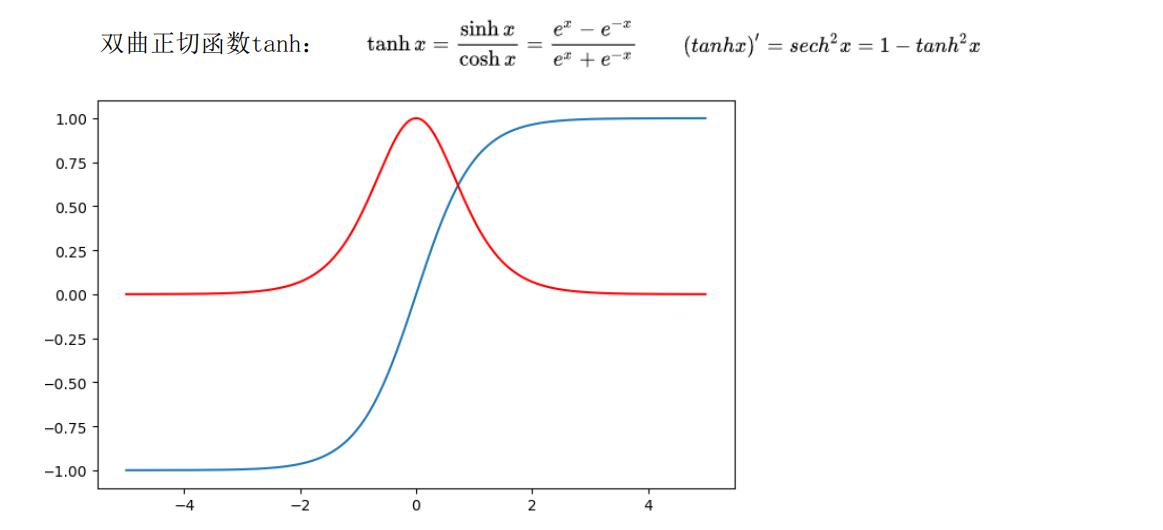
- 优点:
- 函数输出以(0,0)为中心
- 收敛速度相对于Sigmoid更快
- 缺点:
- tanh并没有解决sigmoid梯度消失的问题
ReLU
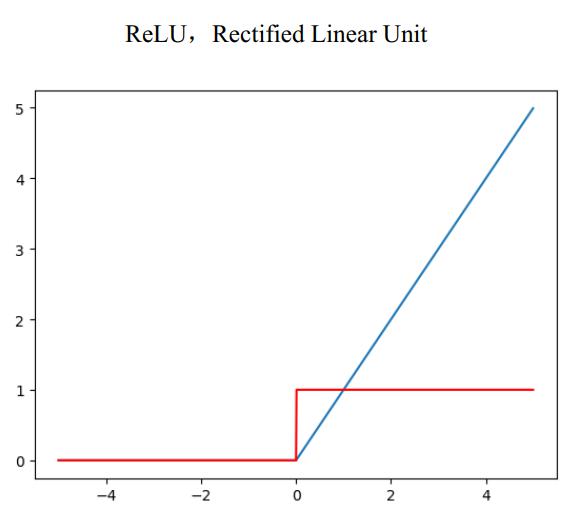
- 优点:
- 在SGD中收敛速度要比Sigmoid和tanh快很多
- 有效的缓解了梯度消失问题
- 对神经网络可以使用稀疏表达
- 对于无监督学习,也能获得很好的效果
- 缺点:
- 在训练过程中容易出现神经元失望,之后梯度永远为0的情况。比如一个特别大的梯度结果神经元之后,我们调整权重参数,就会造成这个ReLU神经元对后来来的输入永远都不会被激活,这个神经元的梯度永远都会是0,造成不可逆的死亡。
2.5 dropout
dropout在训练过程中随机忽略一部分神经元的结果,能够有效减轻过拟合现象。
2.6 批归一化
为了克服特征分布中包含的不利因素,一些归一化方式被提出,并使得网络训练效率大幅提升,以BN(batch normalization) 为例。
BN 的作用和缺陷
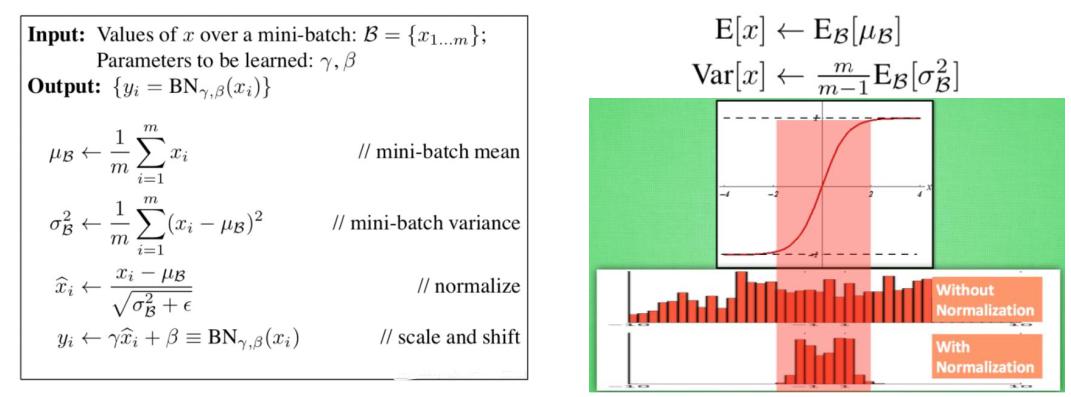
- BN的作用:
- 允许较大的学习率
- 减弱对初始化的强依赖性
- 保持隐藏层中数值的均值、方差不变,让数值更稳定,为后面网络提供坚实的基础
- 有轻微的正则化作用(相当于给隐藏层加入噪声,类似Dropout)
- BN的缺陷:
- 效果与batchsize相关, batch较小时,效果较差
- 对于某些特定的模型,效果不佳,例如RNN
- 训练和测试的统计量不一致
BN、LN、IN、GN 四种不同归一化方式的对比:
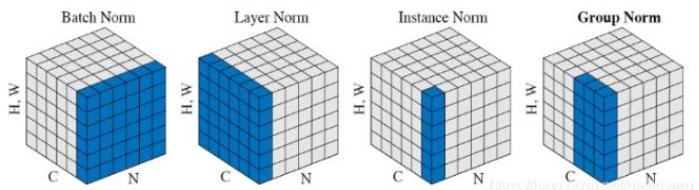
BN 起作用的深层次原因
- 对于输入数据进行标准化操作能够加速学习,那么对于隐藏层来说,学习具有统一分布的数据相对也会更具简单。
- 解决了internal covariance shift问题
- 起到了一定的正则化作用
一篇较新的论文指出, BN的深层次作用机理与internal covariance shift无关,而是平滑了损失函数的landspace, How Does Batch Normalization Help Optimization?
3. 深度学习
3.1 CNN的出现
卷积神经网络与普通神经网络的区别在于,卷积神经网络包含了一个由卷积层和子采样层(池化层)构成的特征抽取器。在卷积神经网络的卷积层中,一个神经元只与部分邻层神经元连接。在CNN的一个卷积层中,通常包含若干个特征图(featureMap),每个特征图由一些矩形排列的的神经元组成,同一特征图的神经元共享权值,这里共享的权值就是卷积核。卷积核一般以随机小数矩阵的形式初始化,在网络的训练过程中卷积核将学习得到合理的权值。共享权值(卷积核)带来的直接好处是减少网络各层之间的连接,同时又降低了过拟合的风险。子采样也叫做池化(pooling),通常有均值子采样(mean pooling)和最大值子采样(max pooling)两种形式。子采样可以看作一种特殊的卷积过程。卷积和子采样大大简化了模型复杂度,减少了模型的参数。
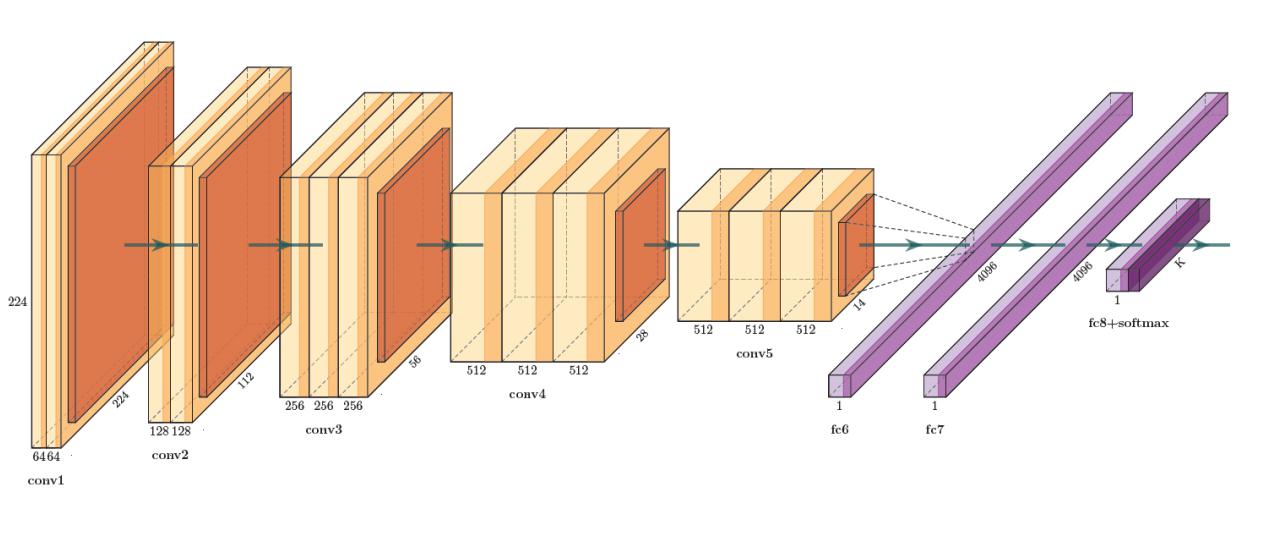
CNN是一种人工神经网络,CNN的结构可以分为3层:
- 卷积层(Convolutional Layer):主要作用是提取特征。
- 池化层(Max Pooling Layer):主要作用是下采样(downsampling),却不会损坏识别结果。
- 全连接层(Fully Connected Layer):主要作用是分类。
基本概念:
- 卷积核:卷积核就是图像处理时,给定输入图像,在输出图像中每一个像素是输入图像中一个小区域中像素的加权平均,其中权值由一个函数定义,这个函数称为卷积核。
- 卷积:卷积可以对应到2个函数叠加,因此用一个filter和图片叠加就可以求出整个图片的情况,可以用在图像的边缘检测,图片锐化,模糊等方面。
3.2 何谓“深度”
为什么要变得更深?
- 提升同样效果需要增加的宽度远远超过需要增加的深度
- 宽而浅的网络可能比较擅长记忆,却不擅长概括,即泛化能力差
网络变得更深要克服哪些问题?
- 误差信号的多层反向传播容易产生“梯度消失”、“梯度爆炸”现象
- 随着深度神经网络层数的增加,训练误差没有降低反而升高
3.3 代表作ResNet
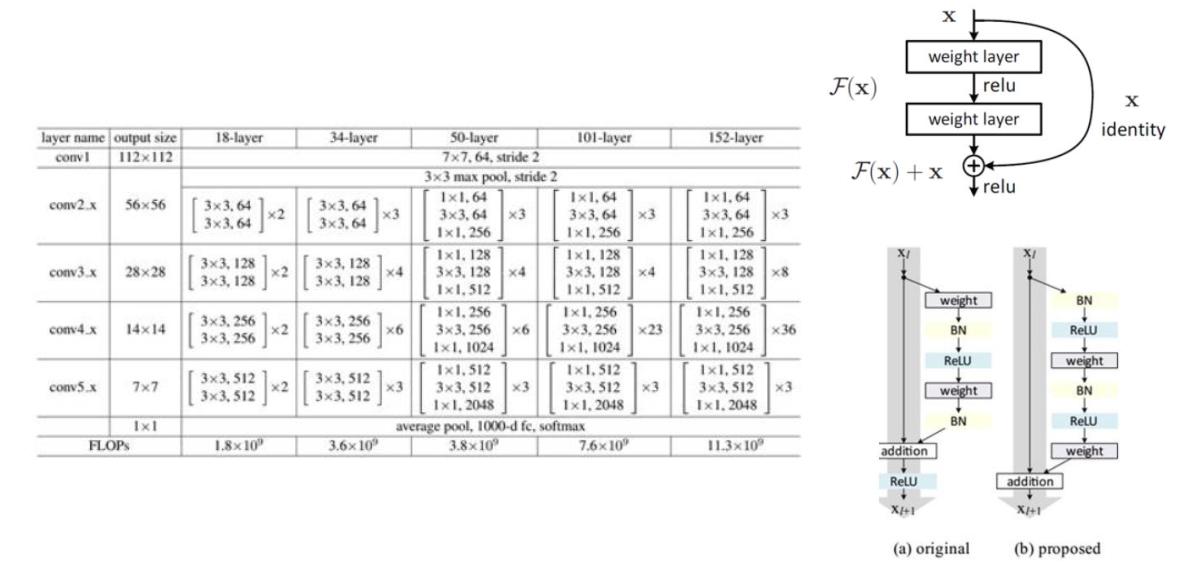
ResNet也称为残差网络,ResNet要解决的是深度神经网络的”退化(degradation)”问题,即使用浅层直接堆叠成深层网络,不仅难以利用深层网络强大的特征提取能力,而且准确率会下降,这个退化不是由于过拟合引起的。