1. 深度学习环境搭建
1.1 Ubuntu
常用的检查服务器环境的命令:
- 检查系统版本:
cat /etc/os-release - 查看显卡信息:
nvidia-smi - 查看CUDA版本:
nvcc –V - CUDA的下载网站:https://developer.nvidia.com/cuda-downloads
1.2 Anaconda
镜像配置
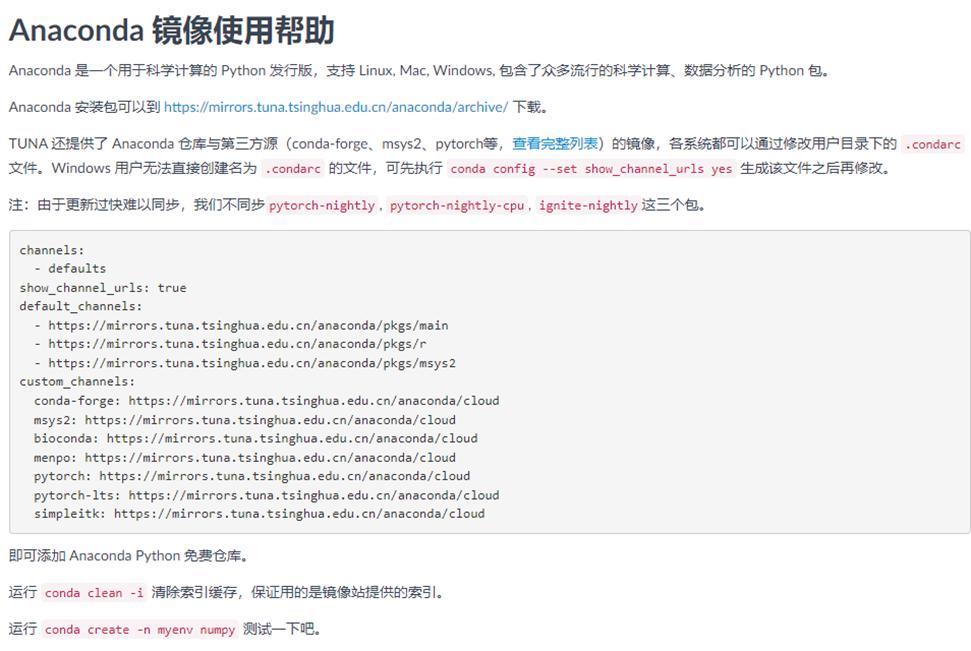
- Anaconda镜像下载地址:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
- Anaconda镜像配置:https://mirrors.tuna.tsinghua.edu.cn/help/anaconda/
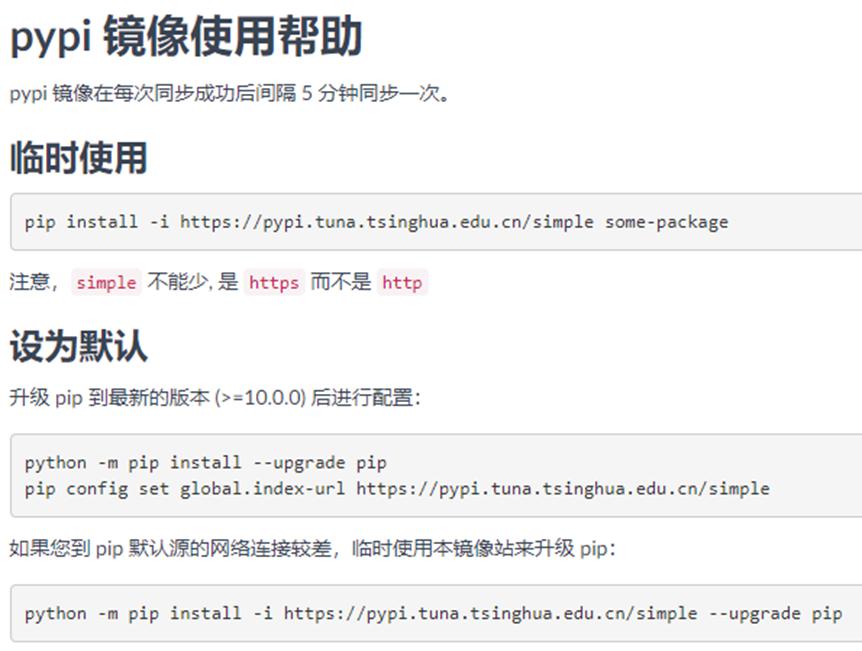
- Pypi镜像配置:https://mirrors.tuna.tsinghua.edu.cn/help/pypi/
Conda环境管理命令
- 创建环境:
conda create -n deep_learning - 查看已有环境:
conda env list - 选择一个环境:
conda activate deep_learning - 退出当前环境:
conda deactivate - 删除一个环境:
conda env remove -n deep_learning
1.3 PyTorch
-
基于清华镜像安装pytorch环境:
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch -
查看环境中pytorch版本:
conda list | grep pytorch -
测试pytorch是否安装成功,以及cuda是否可用:
1 | import torch |
常用命令和工具:
- 查看GPU占用情况:
gpustat –I(gpustat 需要使用conda安装) - 查看驱动详情:
watch -n 0.5 nvidia-smi - 选择要使用的显卡卡号:
export CUDA_VISIBLE_DEVICES=‘2,3’
1.4 开发工具推荐
- MobaXterm:远程连接工具,较 Xshell 而言,有更多的组件。
- PyCharm
- VS code
- Jupyter
2. PyTorch 基本概念
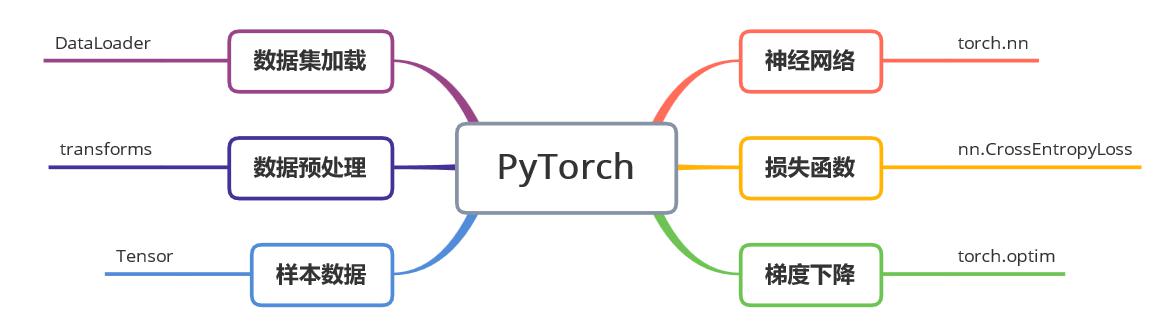
机器学习的过程主要分成数据、网络、损失、随机梯度下降几个模块,这些模块在pytorch中的对应了不同包的实现。
2.1 DataLoader
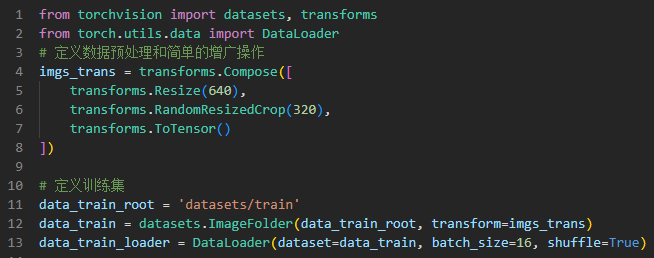
DataLoader数据加载 & transforms数据预处理:
- 指定文件夹为数据集目录,按照固定格式生成数据集;
- Compose以多种transforms编组,对数据做预处理或者增强;
- DataLoader则为每次从数据集中随机选取16个的方式进行选取。
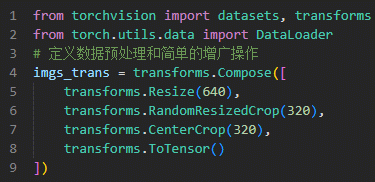
2.2 Transforms
Transforms数据预处理:
- 缩放到固定大小
- 中心裁剪
- 随机裁剪
- 转成Tensor张量的类型
Transforms数据预处理效果:

2.3 Tensor
Tensor张量:Tensor的用法和Numpy中的ndarray非常相似,是PyTorch中重要的操作单元。
1 | from torch import tensor |
2.4 NN
torch.nn神经网络:
1 | nn.Sequential() 序列形式用于组织网络中层级关系 |
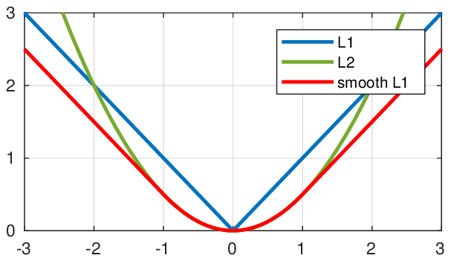
2.5 CrossEntropyLoss
torch.nn.loss损失函数:
- nn.L1Loss():L1绝对值损失
- nn.SmoothL1Loss:区间平滑的L1损失
- nn.MSELoss():L2均方误差损失
- nn.CrossEntropyLoss():交叉熵损失
2.6 Optim
torch.optim优化函数:
- optim.Adam:自适应动量估计优化法
- optim.SGD:随机梯度下降法
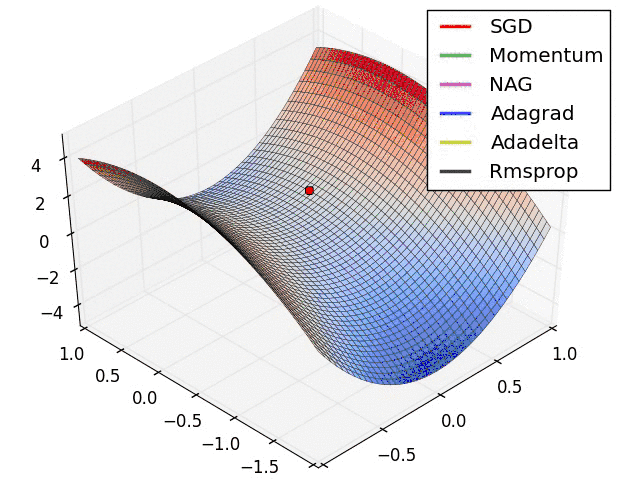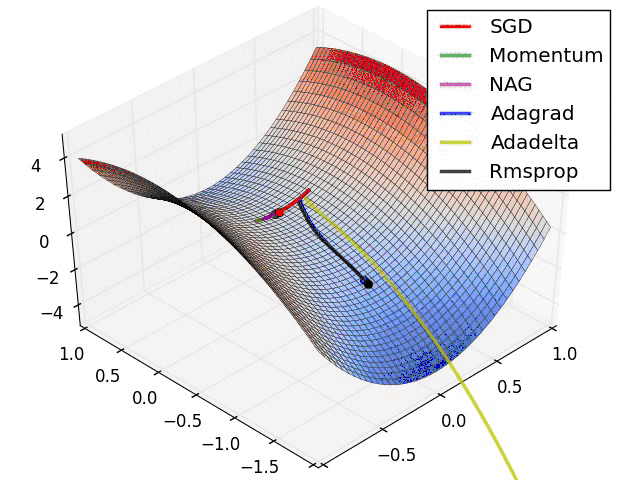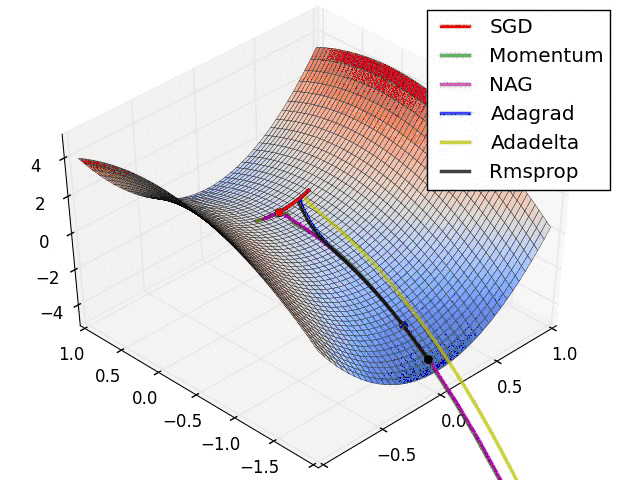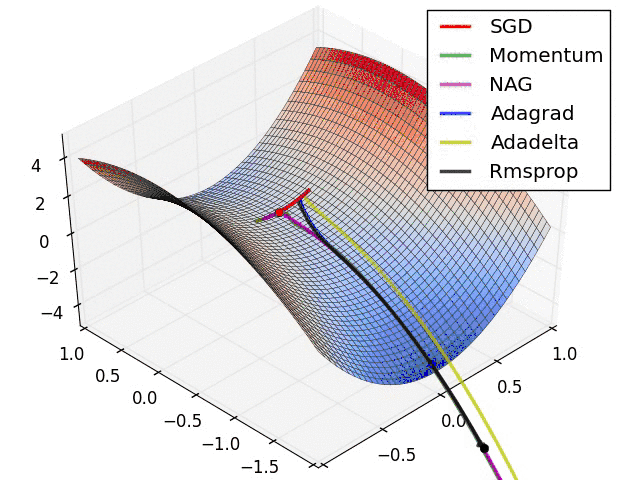
3. 编写图像分类代码
3.1 基本流程
有监督的深度学习的基本流程:
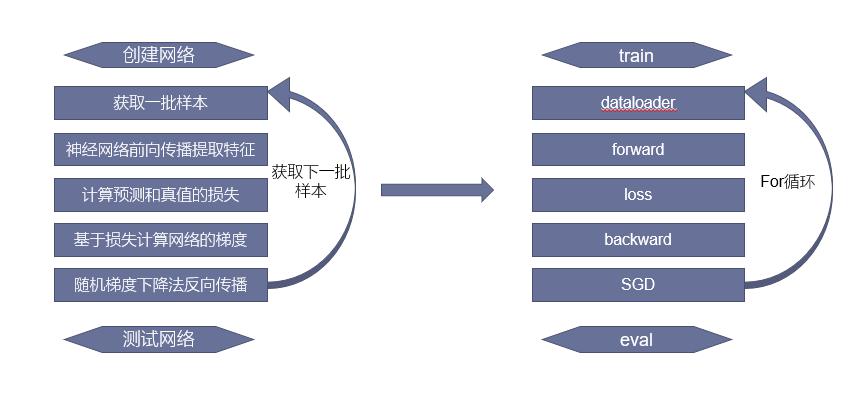
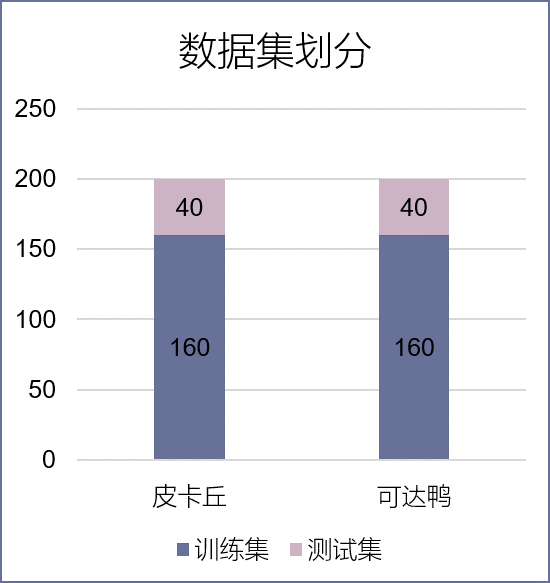
3.2 准备数据
每个类别各200张图片,并划分成训练集和测试集,分别为160张图片和40张图片,
训练集总共有320张图片,测试集则共有80张图片。
皮卡丘数据集:

可达鸭数据集:

数据集划分:
3.3 网络模型设计
以卷积的方式,设计一个五层的卷积特征提取网络,在每一层都进行一次下采样,将提取到的特征使用全连接的神经网络进行计算,得到最终的二分类预测。
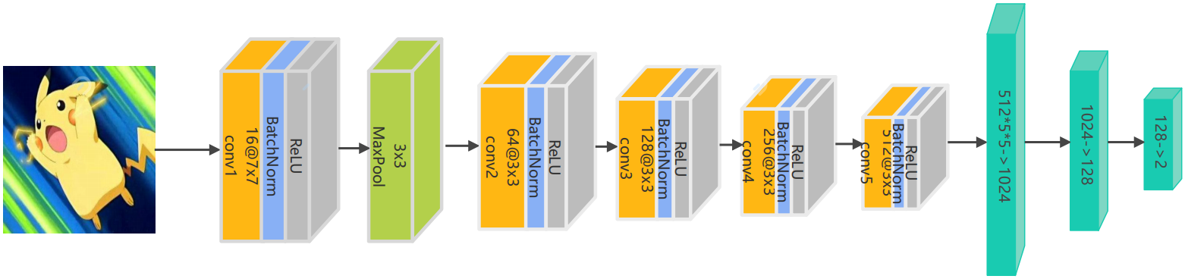
3.4 代码实现
以课程代码为例:
1 | ## 实现皮卡丘和可达鸭的分类 |
4. 学习和编程经验分享
4.1 VS Code 配置
- 安装远程连接插件
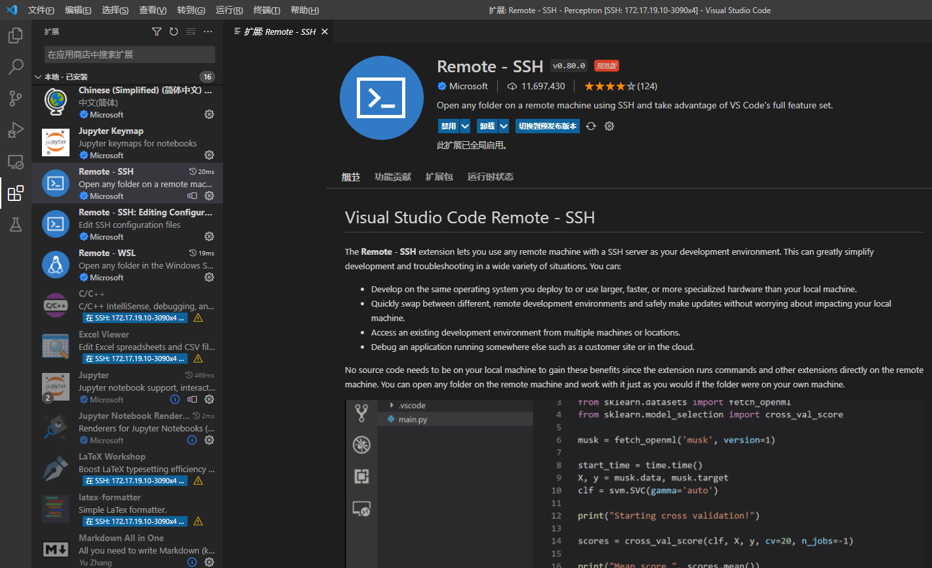
- 配置远程服务器,并远程访问工程目录
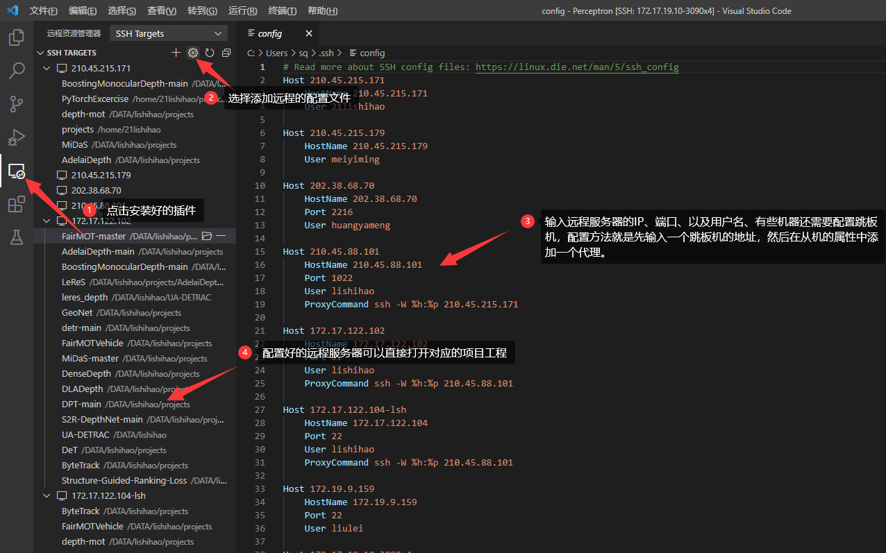
- 代码调试
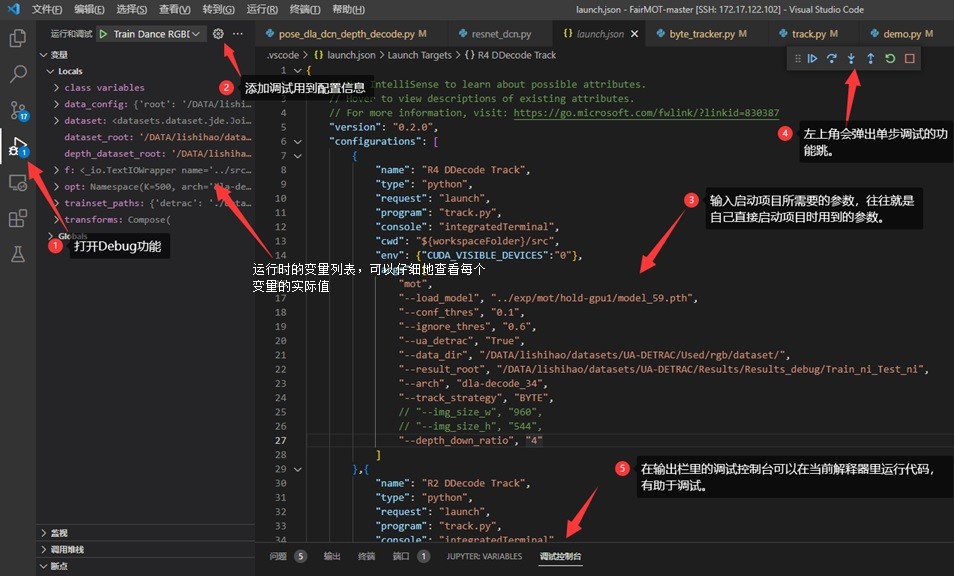
4.2 实验经验
- 训练挂载到后台,有效防止ssh超时导致的训练终断:
nohup python -u track.py > …/logs/log_20220613.log 2>&1 & - 挂载到后台的日志,也可以实时查看训练进展:
tail -fn 100 …/logs/log_20220613.log - 在~/.bashrc中配置一些命令别名,可以节省很多输入命令的时间例如:
alias “nsw”="watch -n 0.5 nvidia-smi”
alias “gst”=“gpustat –I”
alias “ll”="ls -alh“ - 要熟悉Linux下的文件系统,以及相对和绝对两种路径的区别:
绝对路径以”/”开头,相对路径以”…/”开头。
绝对路径从root目录出发,相对路径从当前目录出发。 - 在windows本机安装git,不仅可以用于版本控制,还提供了一个git bash环境方便使用shell命令和脚本。
- 将本机和服务器之间配置免密登录,可以省去每次登录输入密码的时间,对VsCode也同样有效。
- 在学校服务器上下载代码的时候,可以下载到挂载的数据盘上,数据盘空间很大不会因为磁盘没有空间而导致训练终断。(数据盘的位置一般是/DATA或/data)
4.3 常用科研工具
- 阅读文章的工具: ReadPaper、WPS
- 数据集下载和SOTA排名:超神经、Paperswithcode
- 下载论文的代码:Paperswithcode、Github
- Linux命令速查手册
- Python开发文档:
- 镜像网站:
- 神经网络在线模拟可视化